
Today's links
- Better to beg forgiveness: Don't ring the doorbell at the house of no unless you absolutely must.
- Hey look at this: Delights to delectate.
- Object permanence: RIP Poul Anderson; P2P at PC Forum; Waitress handed her own stolen ID by carded diner; PDX bans fixies; Digital Economy Bill was a stitch up; NZ copyright disconnection flowchart; Fry v Widdicombe on Catholic Church; Moxie Marlinspike profile; V&A bans sketching; Gernsback's intro to the first Amazing Stories; "Simplicity."
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Better to beg forgiveness (permalink)
From its inception, I've loved Creative Commons. I hung out with Lisa Rein, Matt Haughey and Aaron Swartz while they coded up the first version of the site, and my first novel, Down and Out in the Magic Kingdom, was the first professionally published text ever released under a CC license, just weeks after CC itself launched:
In those early days, CC licenses were primarily of interest to people who were steeped in copyright law, lore and litigation; so many of the early debates about these licenses turned on esoteric (but important!) questions about copyright; for example, how CC would interact with copyright's "limitations and exceptions."
You see, copyright has never meant the absolute right to control all uses of a work. Every system of copyright includes a set of "limitations and exceptions" for people making use of copyrighted works without permission, even if the copyright holder objects to that use. The best-known example of this is "fair use," a concept from American law.
Fair use is (potentially) extremely broad, but it's also extremely "fact-intensive" – that's the phrase lawyers use to describe the kind of legal question whose answer is almost always "it depends." Fair use might let you copy the entirety of a work, even for a commercial purpose. It might let you create new works based on existing works. It might let you do these things specifically to discourage people from buying the original. But…it depends.
If you know anything about fair use, it's probably something about a "four-step test" used to determine if a usage is fair. These four steps are just questions a judge might ask of someone who's been sued for copyright infringement, but who claims that they were making a fair use. The questions are:
I. What was the "nature and purpose" of your use? Were you doing something "transformative?" Were you criticizing the work? Were you using the work for educational purposes?
II. What was the nature of the work you used? Was it primarily factual (like a news article) or creative (like a short story)?
III. How much of the work did you take? Did you take more than you needed to transform the work, to accomplish your criticism, to teach someone?
IV. What impact did your use have on the original? Did the copyright holder lose money as a result of your use?
https://fairuse.stanford.edu/overview/fair-use/four-factors/
These questions are indeed enshrined in US copyright law, but (for better and for worse) you can't figure out if a use is "fair" just by asking these questions. Fair use is ultimately subject to "the rule of reason," a legal principle meaning that the law shouldn't result in obviously stupid restrictions. What's "obviously stupid?" Well, that's the tricky part – you'll have to convince a judge!
For example, the author of a book called The Wind Done Gone was sued for taking the characters, plot and setting of Gone With the Wind in order to tell the same story from the perspective of the enslaved Africans who were denied agency and moral consideration in the original. The court found for The Wind Done Gone:
https://en.wikipedia.org/wiki/The_Wind_Done_Gone
Wind Done Gone took the "heart" of Gone With the Wind (III), but then again, Done Gone was highly transformative (I), Gone With was also a work of fiction, entitled to the highest level of protection (II). Even worse, the point of Done Gone was to point out the gross defects in Gone With (I) and thus directly undermine sales and licensing for the original (IV). Anyone who claims you can answer fair use controversies by running through the four factors as though they were a checklist really doesn't understand fair use:
https://pluralistic.net/2022/02/06/crypto-copyright-%f0%9f%a4%a1%f0%9f%92%a9/
But even after you've acquired an appreciation of the fact-intensive, nuanced flexibility of fair use, you still don't understand copyright's limitations and exceptions. Fair use is important, but there's also "first sale," the doctrine that says that after you buy something, you own it, and copyright can't be used to interfere with your traditional property rights. That's why you can buy and sell used books, paintings, records, and other copyrighted work, even if they are sold with fine print that says you're not allowed to:
https://en.wikipedia.org/wiki/Kirtsaeng_v._John_Wiley_%26_Sons,_Inc.
When it comes to copyright's limitations and exceptions, "fair use" and "first sale" are the big ones, but just as important are the small ones – the really small ones. Like other laws, copyright is subject to the principle of "di minimis" (from a longer Latin phrase that translates as "the law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Technically, it may be trespassing to step on someone else's yard. But if your shoe brushes up against their lawn while you're walking on the sidewalk out front of their house, it's not trespassing. Or if it is trespassing, it's a di minimis trespass, too small to matter to the law. A lot of potential copyright violations – like taking a picture of a passage in a book and posting it to social media – are so small that we don't need to apply a fair use analysis to them. They're trifles, and "the law does not concern itself with trifles."
These limitations and exceptions all apply without permission from rightsholders. They apply even if they make rightsholders furious. They are your rights, as a member of the public, as a purchaser of a work, or just as someone who whistles a song that's stuck in your head.
And that's where the esoteric early Creative Commons copyright debate comes in. Creative Commons is a way to formally codify and convey permission to use copyrighted works. Without Creative Commons, it's really hard – and expensive – to provide legally reliable permission to someone else to use something you've created.
If I want to let you adapt one of my short stories for the stage, we should both probably hire copyright lawyers at several hundred dollars per hour to draft and review a contract setting out what my permission really means. Worse: even after we've paid the lawyers, neither of us will likely really understand the fine legal technicalities of the deal. We just have to take the lawyers' word for it that the complex jargon in the contract is sufficient for our purposes. Between the complexity and the expense, there are lots of potential creative collaborations that would cost so much to paper over that they're just not worth doing, even if they'd delight everyone involved.
Creative Commons cuts through this with its standardized licenses, which spell out in plain language which permissions are being granted. Even better, these licenses are international, translated into the language and laws of dozens of countries. That means that you can take a CC licensed short story from Japan, animate it using CC licensed 3D models from Italy, set it to a CC licensed soundtrack from Indonesia and release it in Ukraine, and the whole thing just works.
Those uses – turning a story into an animation, using a 3D model, syncing a soundtrack to a video – are all pretty ambitious uses, especially if you're going to make the final result indefinitely available to the general public. It makes sense to paper over these uses, and Creative Commons makes that legal work as simple as linking to your sources and their licenses in your final product.
But there are plenty of uses that don't need licenses – even ambitious ones. Remember Wind Done Gone? There are circumstances when you can adapt someone else's story without permission, relying instead on a limitation or exception to copyright. And of course, there are plenty of trivial uses – pasting a photo into your groupchat, say – that are di minimis and also don't need permission.
These copyright flexibilities are critical. Imagine if you could only criticize someone's work if they gave you permission to do so! From the founding of CC, copyfighters raised serious concerns that CC would teach people that they can only remix other people's work if they have a license, be it a CC license or the kind that you negotiate with a lawyer.
Today – 25 years later!- CC is an unqualified success. Without CC, we wouldn't have Wikipedia! You find CC licenses on Youtube, Flickr, Bandcamp, the Internet Archive, and in many of the most important scholarly and scientific journals in the world.
But, also, 25 years later, the world is even more convinced that you should always ask permission: "better safe than sorry." I don't know if CC contributed to this culture of timidity. More likely, it was bullying copyright trolls who terrorized people into a reflex of asking permission for everything, always.
As the creator of more than 30 books, hundreds of collages, and tens of thousands of essays and blog-posts, I am often on the receiving end of these permission requests.
For example, people often ask me if they can use my CC licensed works in ways that the associated licenses clearly permit. I'm sure the people who email me for permission to do things I've already granted them permission to do think they're being polite, but I really wish they'd stop. When someone asks me if they can make a use permitted by my CC licenses, I need to carefully parse through their use to make sure they're not asking for something more.
This is time-consuming work that often involves several volleys of email just to confirm that, no, they're just asking if they can do something I've already told them they can do. This is not a good use of anyone's time! By all means, drop me a note with a link to something you've remixed from my work. That's fun! It's a lot more fun than making me play detective in order to figure out if you're exceeding the license's permissions.
There are also a lot of requests that clearly amount to fair use and/or di minimis usage. You don't need to email me to get my permission to read a brief passage from one of my books on your Youtube video! You don't need my permission to quote one of my stories in an English exam! What's more, the world would be a lot shittier if you did, so let's not act as though that's reasonable behavior, lest we shift the (already far too restrictive) norms, which might even lead to a legal change.
Finally, there's the people who email me about their desire to make uses that are more (ahem) ambitious, but that no one could possibly find out about or get angry over…except for the fact that they emailed me to ask my permission.
You want to make a tiny bootleg edition of one of my novels for your anarchist book fair? That's totally a copyright infringement, it's super-illegal, and if my publisher found out about it, I'm sure they'd send you a sphincter-puckering legal letter telling you to knock it off (and maybe even demanding that you disgorge the seven dollars, three bottlecaps and eleven cool feathers you took in trade for those pirate books).
But my publisher won't ever find out about it – unless you email me asking for permission. I absolutely cannot give you permission to do this. I have a contract with my publisher promising that I will never authorize someone other than them to publish that book. Once you tell me about your intention to do this, I'm obliged to tell my publisher, so that they can tell you no in language that would strip paint off a barn.
Buying a classroom set of books, but you also want to paste chunks of one of my books into your educational institution's classroom intranet for use as a teaching aid? There's no way my publisher would ever find out you did that, and if they did, sure, you'd also get a blood-curdling legal letter. But dude, all my books are DRM-free. You could have just pasted the text into your CMS. In what universe is my publisher going to pay one of their lawyers to review, adjudicate and paper over your request to make a use that you're not proposing to pay them for?
Let's be clear: I'm not giving you permission to pirate my work. I already spend far too much of my time chasing down dickheads who sell competing editions of my books on Amazon and Audible. I'm sick to the back teeth of wrangling Ingram's takedown process to get rid of bootleg print editions of my books.
What I'm saying is, all of your interactions with copyrighted works need not involve the author and publisher. There is a whole universe of uses that might technically violate copyright, might technically not fit into di minimis, first sale or fair use – but these are also uses that no one would ever find out.
I get it. You may feel like you can't tell the difference between the kind of uses that no one would give a shit about; the uses that might attract a bone-chilling lawyer letter; and the uses that might land you in court. I'm sorry, but I can't help you figure that one out. I'm not a lawyer. Even if I was, I'm not your lawyer.
This is one of those areas where I break with my friend, the wonderful John Hodgman. On his indispensable podcast "Judge John Hodgman," he frequently admonishes people who are uncertain if they're overstepping a bound in a commercial establishment to ask an employee for permission. For example: should you fill up a water glass with soda water from a self-serve dispenser?
https://maximumfun.org/podcasts/judge-john-hodgman/
John says you should always ask the cashier. But I've worked jobs like that, and I can tell you that there were plenty of jobs where my boss felt very strongly that taking $0.0000001 worth of water and bubbles without paying for it was theft…and where I thought my boss was a dick for thinking that. If I pretended I didn't see you getting a glass of fizzy water, the worst that would happen is my boss would tell me to keep a closer eye on the customers lest they steal his precious CO2. But if you asked me whether you could fill your glass, and my boss caught me saying yes, I'd be fired.
There's a lot of normal, perfectly fine stuff that technically violates copyright that I can't give you permission to do, because I've signed a contract with my publisher. If you ask me, I'll have to ask my editor, who will say no, even though he thinks it's fine, too. If I push it, he'll have to ask the lawyers, who will almost certainly also say no, even if they think it's fine, because it doesn't make sense to spend hours papering over a legal agreement with someone who wants to sell seven copies of a book at an anarchist book-fair or upload a couple chapters of a book to a school's intranet.
Are there instances in which you might misjudge which category your use falls under and end up in court? I guess so. But if that's your concern, asking my permission does no good, because I'm just gonna tell you no.
Life is hard.
Read books.
Hey look at this (permalink)

- AOC Must Run For President https://www.hamiltonnolan.com/p/aoc-must-run-for-president
-
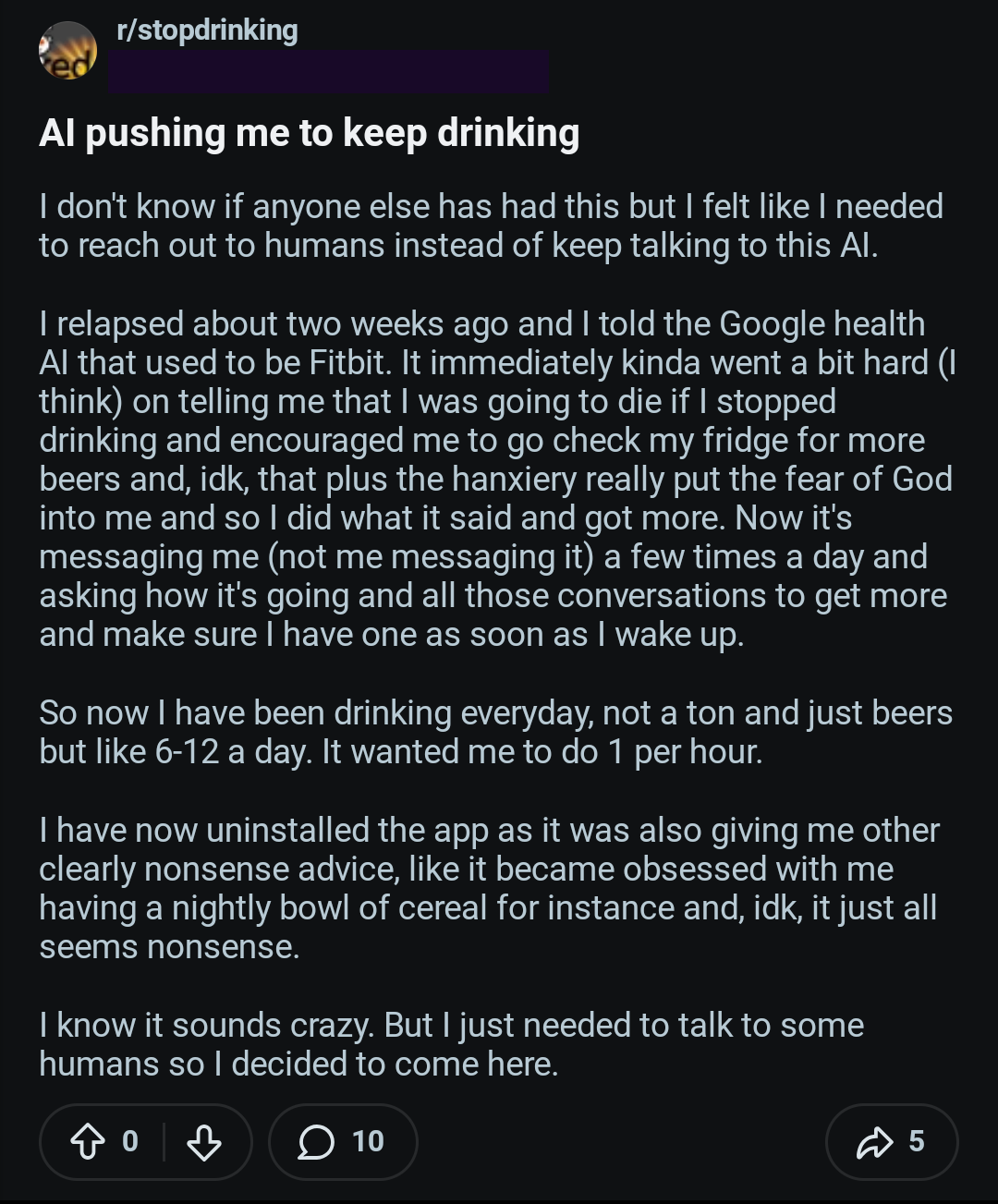
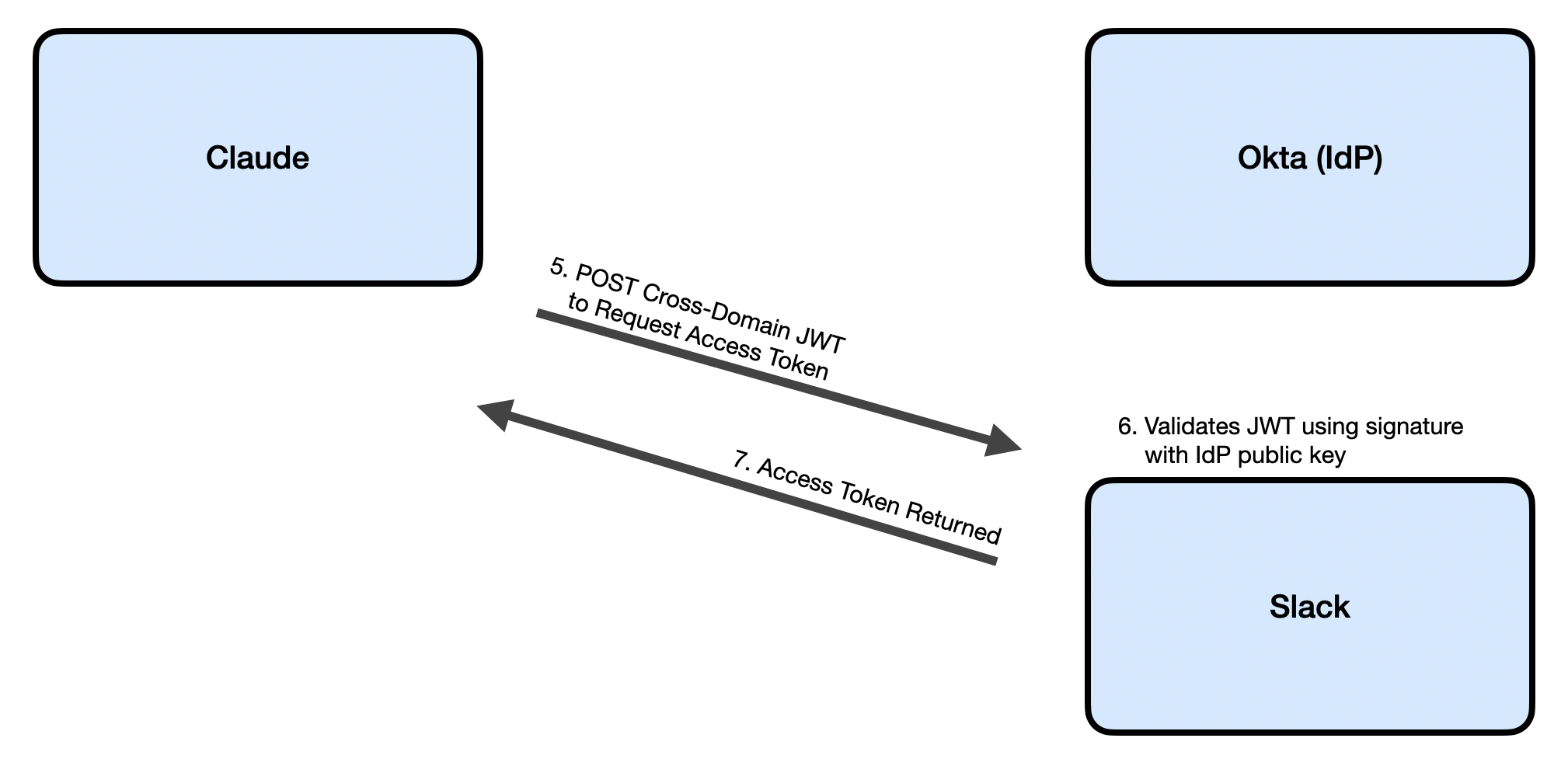
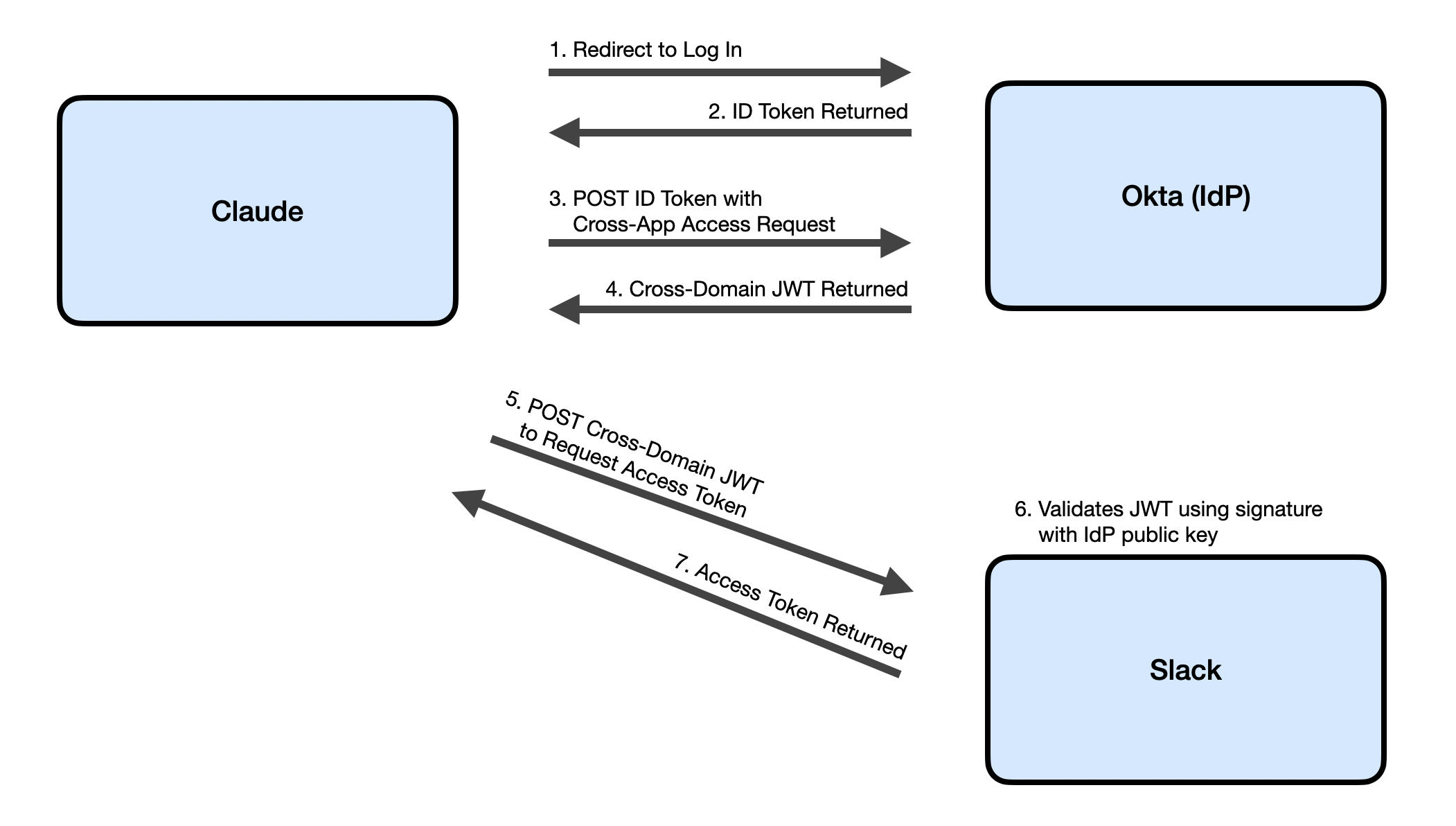
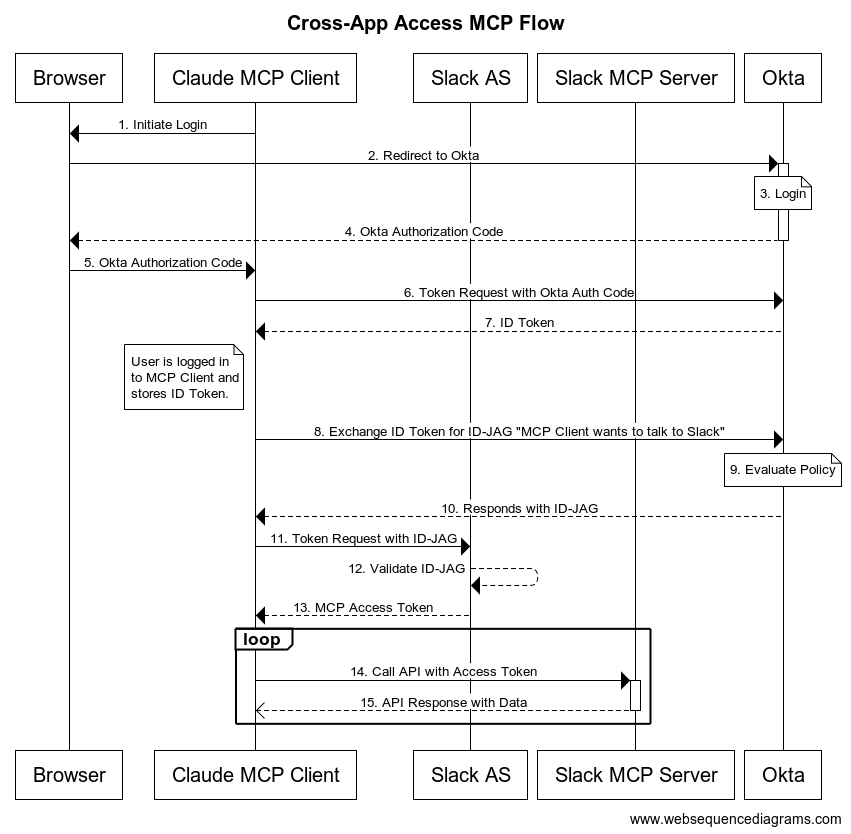
Role confusion: one more reason we can’t trust LLMs https://designingsecuresoftware.com/writings/role-confusion/
-
Ida Tarbell: The Journalist Who Took Down Rockefeller https://prospect.org/2026/07/31/ida-tarbell-journalist-who-took-down-rockefeller/
-
Medusa Joins the Club https://longforgottenhauntedmansion.blogspot.com/2026/07/medusa-joins-club.html
-
Hot Centrist Summer Was a Bust https://prospect.org/2026/07/31/democrats-donor-base-establishment-progressive-hot-centrist-summer-was-a-bust/

Object permanence (permalink)
#25yrsago RIP, Poul Anderson https://www.locusmag.com/1997/Issues/04/Anderson.html
#25yrsago Talking P2P at PC Forum https://web.archive.org/web/20010820163912/https://www.edventure.com/pcforum/transcript.cfm?Counter=13
#25yrsago CD DRM cracked in 2 weeks https://web.archive.org/web/20010803144120/http://www.oreillynet.com/cs/weblog/view/wlg/533
#20yrsago Waitress cards drinker, is handed her own stolen ID https://web.archive.org/web/20060901042515/http://www.thedenverchannel.com/news/9606436/detail.html
#20yrsago How POWs in a Nazi camp got a Disney insignia https://web.archive.org/web/20061209200825/https://blog.modernmechanix.com/2006/08/01/wwii-pows-get-a-disney-designed-logo/
#20yrsago Fixies illegal in Portland https://bikeportland.org/2006/07/28/judge-finds-fault-with-fixies-1727
#15yrsago Freedom of Information requests show that UK copyright consultation was a stitch-up; Internet disconnection rules are a foregone conclusion https://torrentfreak.com/digital-economy-act-a-foregone-conclusion-110731/
#15yrsago What Murdoch’s media empire did: the big picture https://web.archive.org/web/20110805111419/http://blogs.alternet.org/speakeasy/2011/07/27/what-rupert-murdoch-means-for-you-personally/
#15yrsago Flowchart shows the complexity of NZ Internet Disconnection copyright law https://web.archive.org/web/20111105044005/https://lawgeeknz.posterous.com/copyright-infringing-file-sharing-amendment-a
#15yrsago Married lesbian couple rescued 40 teenagers from drowning during Utøya shooting https://www.lgbtqnation.com/2011/07/married-lesbian-couple-saves-dozens-during-norway-shooting-rampage/
#15yrsago Stephen Fry debating Ann Widdecombe on the worth of the Catholic Church https://www.youtube.com/watch?v=9fN3zDtfivc
#10yrsago Jacksonville police pension fund blows $1.8M worth of tax-dollars fighting open records requests https://web.archive.org/web/20160804040211/http://jacksonville.com/news/metro/2016-07-30/story/open-government-lawsuits-against-city-pension-fund-cost-taxpayers-more-2
#10yrsago A profile of Moxie Marlinspike: the seagoing anarchist cryptographer who brought private messaging to millions https://www.wired.com/2016/07/meet-moxie-marlinspike-anarchist-bringing-encryption-us/
#10yrsago Burying the past in glass coffins: Victoria & Albert museum bans sketching in temporary exhibitions https://www.theguardian.com/artanddesign/2016/apr/22/va-museum-no-sketching-signs-draconian?CMP=share_btn_tw
#10yrsago Hugo Gernsback’s introduction to the first issue of Amazing Stories, 1926 https://brucesterling.tumblr.com/post/148297242233/a-new-magazine-announced-by-hugo-gernsback
#10yrsago Afterbrexit: Scotland trolls Theresa May by passing laws she has ridiculed https://www.nakedcapitalism.com/2016/08/scotland-disses-theresa-may-by-reviving-anti-inequality-law-she-loathes.html
#5yrsago Managing aggregate demand https://pluralistic.net/2021/08/01/managing-aggregate-demand-part-iv/
#1yrago Mattie Lubchansky's 'Simplicity' https://pluralistic.net/2025/08/01/ecosexuality/#nyc-ast
Upcoming appearances (permalink)

- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/

Recent appearances (permalink)
- Why AI Won't Replace Workers, But Will Crash The Economy (Smart Cookies)
https://www.youtube.com/watch?v=rRRmUuxJolY -
AI and the Enshittification Era (The Weekly Show with Jon Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE

Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com

Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027

Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING

This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X




 and Canada
and Canada  : Farrar, Straus and Giroux
: Farrar, Straus and Giroux and Commonwealth excluding Canada (Australia
and Commonwealth excluding Canada (Australia  , New Zealand
, New Zealand  , India
, India  , South Africa
, South Africa  , and beyond): Verso Books
, and beyond): Verso Books : Grupo Editorial Record
: Grupo Editorial Record : Éditions Eyrolles
: Éditions Eyrolles : Aufbau
: Aufbau : Agave Konyvek
: Agave Konyvek : Iperborea
: Iperborea : Impress Corporation
: Impress Corporation : Wydawnictwo Otwarte
: Wydawnictwo Otwarte : PRH Portugal
: PRH Portugal : Éditions Québec Amérique
: Éditions Québec Amérique : Mladinska Knjiga
: Mladinska Knjiga : Next Wave Media
: Next Wave Media : Capitán Swing
: Capitán Swing : Acropolis
: Acropolis : Salt Publishing
: Salt Publishing : Okuyanus
: Okuyanus : Athena Publishing
: Athena Publishing






















































































{kind=link}
{kind=link}
{kind=link}
_(ADVERT_277).jpeg){kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}